面试问题归纳
- 为什么使用dubbo而不使用maven打包jar进行服务调用?
dubbo:跨系统通信。
dubbo需要将服务器B(提供方)的接口类打成包,服务器B(提供方)去实现,客户端A(消费方)去调用。
比如:两个系统,一个系统A作客户端,一个系统B作服务器, 服务器B把自己的接口定义提供给客户端A,
客户端A将接口定义在spring中的bean。客户端A可直接使用这个bean,就好像这些接口的实现(即服务器B的代码)
也是在自己的代码里一样。客户端A和服务器B在启动的时候都会把自己的机器IP注册到zookeeper上,
客户端A会把zk上的服务端ip拉到磁盘上,并记录哪些ip提供哪些服务(服务端启动时暴露给zk),
然后客户端根据ip调用服务端的服务。
maven依赖:在一个多module的maven项目中,maven子模块间提供依赖实现调用。比如模块A调用模块B,将模块B打包成jar, 引入到模块A中(相当于模块A拥有了模块B),实则模块A和模块B是在同一项目中运行。而dubbo的提供者和消费者是两个独立的 服务(A只是调用B,并未拥有B)
- RPC好,还是Restful好?
知乎上被赞最多的一个答案:JSON-RPC比RESTful API好很多。
老夫个人理解其实是将不同的设计模式归纳出的两个名称而已。
restful首先是要求必须把所有的应用定义成为“resource”,然后只能针对资源做有限的四种操作。
这是对API一个非常糟糕的抽象,有太多现实中需要的API,无法顺当的融入到restful所定义的规范中。
比方说,user login / resetpassword等等。
所有的接口,服务器端原本就存在有相应的函数,它们本来就有自身的命名空间,接受的参数、返回值、异常等等。
对应到web上,rpc的成熟方案非常多,有古老的soap,也有轻量的json rpc。
很多json rpc是供web前端ajax调用,若前端调用抽象得当,调用远程API,实际上与调用本地函数无甚区别。
restful API仅适用与业务非常简单的场景,比方说,就是为了提供少量数据表单的增删改查。
而这种场景实在是太过简单,实际中几乎找不到。
- MyBatis编程步骤?
① 创建SqlSessionFactory
② 通过SqlSessionFactory创建SqlSession
③ 通过sqlsession执行数据库操作
④ 调用session.commit()提交事务
⑤ 调用session.close()关闭会话
- 线程认知
线程安全问题都是由全局变量及静态变量引起的。
1)常量始终是线程安全的,因为只存在读操作。
2)每次调用方法前都新建一个实例是线程安全的,因为不会访问共享的资源。
3)局部变量是线程安全的。因为每执行一个方法,都会在独立的空间创建局部变量,它不是共享的资源。
局部变量包括方法的参数变量和方法内变量。
无状态:无状态方法的好处之一,就是它在各种环境下,都可以安全的调用。
自己写公用类的时候,要对多线程调用情况下的后果在注释里进行明确说明
对线程环境下,对每一个共享的可变变量都要注意其线程安全性
我们的类和方法在做设计的时候,要尽量设计成无状态的
使用ThreadLocal:也是将共享变量变为独享,线程独享肯定能比方法独享在并发环境中能减少不少创建对象的开销。 如果对性能要求比较高的情况下,一般推荐使用这种方法。
public class ConcurrentDateUtil {
private static ThreadLocal<DateFormat> threadLocal = new ThreadLocal<DateFormat>() {
@Override
protected DateFormat initialValue() {
return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
}
};
public static Date parse(String dateStr) throws ParseException {
return threadLocal.get().parse(dateStr);
}
public static String format(Date date) {
return threadLocal.get().format(date);
}
}
- IOC(控制反转)和DI(依赖注入)的理解:
两都实际上就是一个东西,都是依赖容器来生成特定的bean对象。
Spring-aop用的就是动态代理来实现的,可以加入自己的业务逻辑,比如事务控制、日志管理、缓存机制等, 可以通过配置连接点等信息,在指定类中的方法执行前、执行中、执行后、抛出异常时,调用预先写好的方法进行处理, 比如进入某个方法前 打印日志信息等。
- mysql大小写:
[Linux] MySQL在linux下数据库名、表名、列名、别名大小写规则
[Windows] MySQL在Windows下数据库名、表名、列名、别名都不区分大小写
如果想大小写区分则在my.ini 里面的mysqld部分 ,加入 lower_case_table_names=0
注意:Windows中即使改了这个设置,在查询时还是不会区分大小写。只是在导入导出时会对大小写有区别。
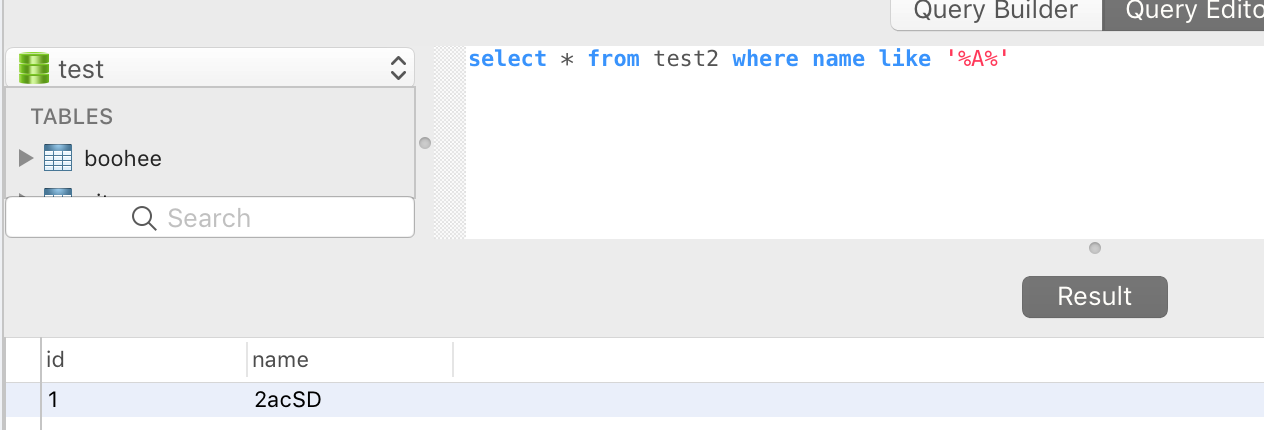
- 查询时where条件是否区分大小写
取决于库或表上的collate(核对、对比) 属性的值。
例如我们使用UTF8编码,collate使用utf8_bin时区分大小写,collate使用utf8_general_ci时不区分大小写
建库语句:
CREATE DATABASE mydb DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci; (不区分大小写)
建表语句:
CREATE TABLE test2(id int(10),name char(10))
ENGINE = InnoDB
COLLATE = 'utf8_bin'; (区分大小写);
CREATE TABLE test2(id int(10),name char(10))
ENGINE = InnoDB
COLLATE = 'utf8_general_ci'; (不区分大小写)
建表时指明了collate,则对对表有效。建表时未指明collate,则使用库上的collate属性。
不区分大小写:
 ⤧ Next post 2017-07-24-开放平台 ⤧ Previous post Spring Boot 搭配踩坑
⤧ Next post 2017-07-24-开放平台 ⤧ Previous post Spring Boot 搭配踩坑