大数据集群部署与管理
大数据在我们的生活中,发挥着越来越明显的作用。比如,大数据辅助购物平台推荐适合客户的产品,大数据辅助避免堵车,大数据辅助做健康检查,大数据娱乐等。
如果想从大数据中获利,数据的采集、挖掘和分析等环节缺一不可,其中,大数据分析技术是重中之重,目前的大数据分析技术有 Hadoop、Spark、Strom 中。
大数据集群技术的架构与分析
一般来说,大数据集群的构架,主要分为几层:硬件层、OS 层、基础设施管理层、文件系统层、大数据集群技术层以及上层应用,如下图所示

并行的文件系统,是大数据集群的重中之重,因为大数据有两个主要的特征,其一是数据量比较大,起步可能就以 PB 为单位,如此巨量数据的存储成为了集群 需要解决的关键问题之一;另外一个特征是处理速度要快,随着集群技术的发展,并行化的思想尤为明显,并行化的计算产品和工具也层出不穷。所以,并行的 文件系统是大数据集群中不可或缺的一部分。比如,在 Hadoop 时代,HDFS 就在 Hadoop 阵营中,贡献了中流砥柱的作用。另外一个出色的并行文件系统为 IBM Spectrum Scale,其前身为 IBM GPFS,经过近来的版本迭代和发展,已经完美的支持目前流行的大数据计算模式,比如 Spark 等。
在资源管理和大数据集群层,主要部署两方面的组件,一是大数据分析处理组件,二是资源调度和管理组件。在一般情况下,这二者都是有机的结合在一起, 组成一个产品。随着大数据的发展,大数据的分析和处理技术如井喷一般涌现出来。比如有 Hadoop, Spark, Storm, Dremel/Drill 等大数据解决方案争 先恐后的展现出来,需要说明的是,这里所有的方案不是一种技术,而是数种,甚至数十种技术的组合,就拿 Hadoop 来说,Hadoop 只是带头大哥,后面的 关键的小弟还有:MapReduce, HDFS, Hive, Hbase, Pig, ZooKeeper 等等,大有”八仙过海,各显神通”的气势和场面。资源调度管理,主要是维护、 分配、管理、监控软硬件资源,包括节点、网络资源、CPU、内存等,根据数据处理的需求来分配资源,并负责回收。
大数据集群的管理与监控
PS:罗列出你的数据源
所有的数据源都有一个共性,就是日志。无论文本的也好,二进制的也好。所以日志是整个信息的源头。日志包含的信息足以让我们追查到下面几件事情:
- 系统健康状况监控
- 查找故障根源
- 系统瓶颈诊断和调优
- 追踪安全相关问题
- 从日志我们可以挖掘出什么?
我觉得抽象起来就一个: 指标。指标可以再进行分类:
- 业务层面,如团购业务每秒访问数,团购券每秒验券数,每分钟支付、创建订单等
- 应用层面,每个应用的错误数,调用过程,访问的平均耗时,最大耗时,95线等
- 系统资源层面:如cpu、内存、swap、磁盘、load、主进程存活等
- 网络层面: 如丢包、ping存活、流量、tcp连接数等
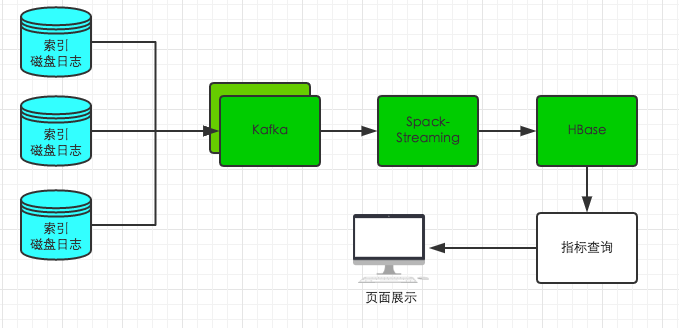
统一查询引擎
其实个人感觉还是淘宝的这种架构方式不错:
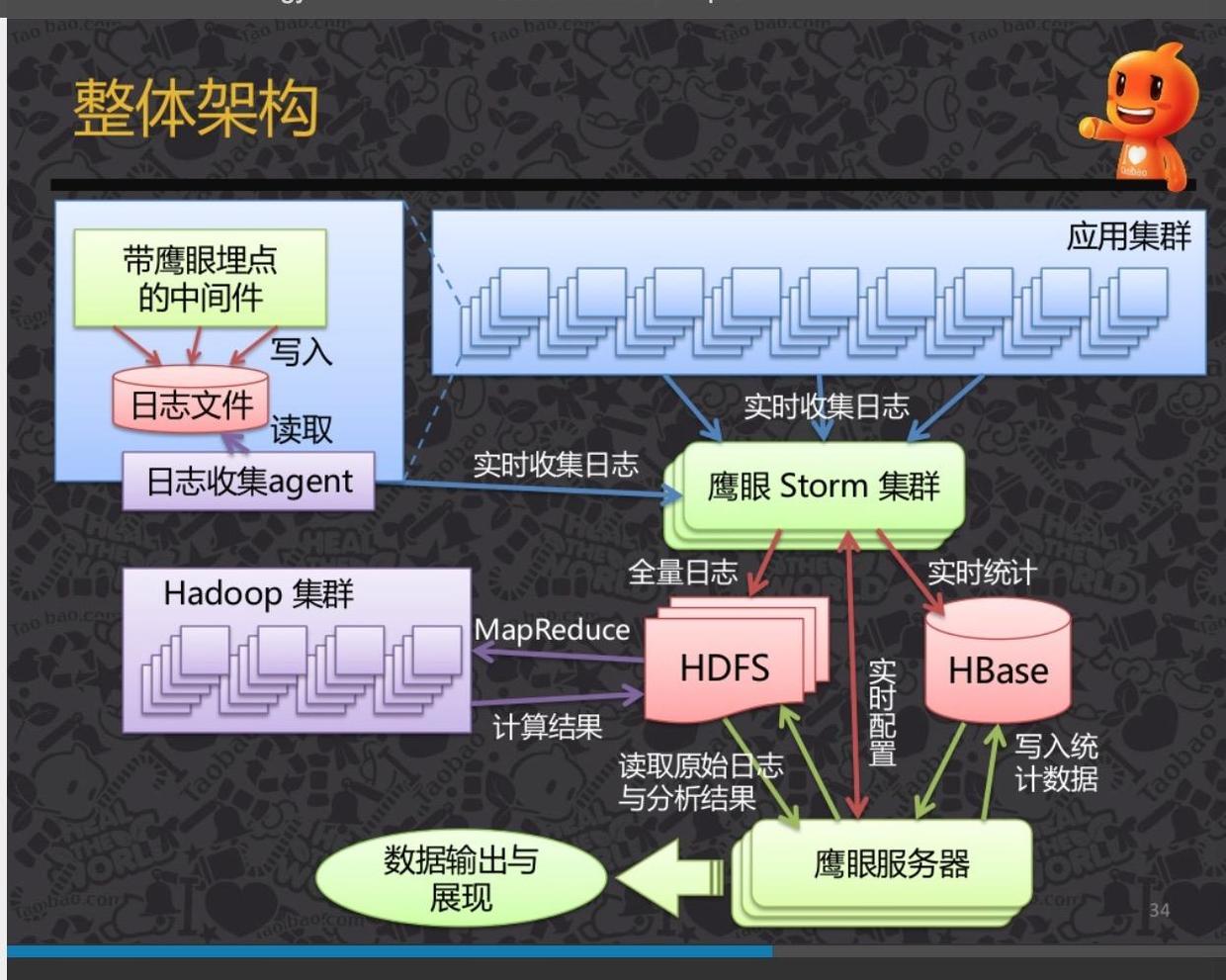
PS:日志收集Agent可以使用Flume,鹰眼Storm集群,其实就是Storm集群,当然有可能是淘宝内部Java版的。
Storm(或第一幅图的SparkStreaming)做两件事情
- 将日志过滤,格式化,或存储起来
- 进行实时计算,将指标数据存储到HBase里去
描述到这,我们可以看到,这套架构的优势在哪:
- 基本上没有需要自己开发的系统。从日志收集,到日志存储,到结果存储等,统统都是现成的组件。
- 可扩展性好。每个组件都是集群模式的,没有单点故障。每个组件都是可水平扩展的,日志量大了,加机器就好。
- 开发更集中了,你只要关注日志实际的分析处理,提炼指标即可。
大数据思维
对于运维的监控,利用大数据思维,需要分三步走:
- 找到数据
- 分析定义从数据里中我能得到什么
- 从大数据平台中挑选你要的组件完成搭积木式开发
PS:还是需要统一产品线日志格式
结束语:
本文参考IBM大数据集群部署 以及用大数据思维做运维监控等文章。 ⤧ Next post 非关系型数据库(NoSQL) ⤧ Previous post HBase的一些关键特性